
Yapay zeka ve makine öğrenimi teknolojileri olgunlaştıkça, araştırmacıların merak konusu olmaktan endüstriyel düzeyde kullanılan araçlar olmaya başladılar. Bununla birlikte de kullanılan yöntemler ve gerekli altyapı değişmeye başladı. Yapay zeka, makine öğrenmesi dünyasındaki bu gelişmeler, sektörlerinde rekabet avantajı elde etmek için bu konular ile ilgilenmek isteyen şirketler için bir yandan büyük fırsatlar ortaya koyarken bir yandan da ciddi riskler oluşturuyor.
Alex Krizhevsky, Illya Sutskever ve Geoffrey Hinton’dan oluşan muhteşem ekibin ImageNET yarışmasını kazandıkları AlexNet modeli ile derin öğrenme dünyasında devrim yapmalarının üzerinden sadece 10 yıl geçti. Bu üç kişilik ekip, fotoğrafların içeriğini anlayabilmek için yedi katmanlı bir evrişimli sinir ağı (Convolutional Neural Network, CNN) modeli kullanmışlar ve bu modeli de video oynamak için kullanılan 700 dolarlık bir grafik kartı ile eğitmişlerdi. Makine öğrenmesi modeli eğitimi için ilk kez GPU kullanmaları, o yarışmada rakiplerine büyük fark atmalarını sağlamakla kalmadı, makine öğrenmesi, derin öğrenme dünyasında yeni bir çığır açılmasına neden oldu.
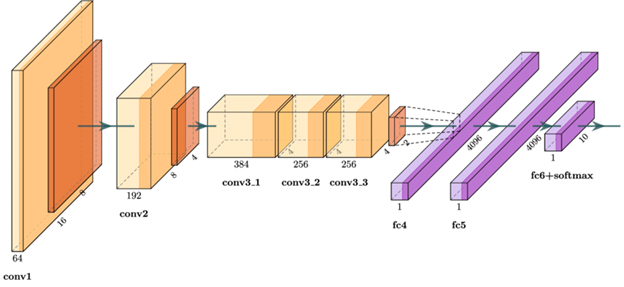
AlexNet ve sonrasındaki bir kaç gelişme ile birlikte makine öğrenmesi dünyası sonsuza dek değişmiş oldu. Gelişmeler, konuyla ilgilenmekte çekingen davranan IBM, Google, Microsoft gibi büyük şirketlerin dikkatini çekti. Öncü start-up girişimler büyük firmalar tarafından satın alınmaya başlandı. Pek çok uzmanın yapay zeka konusundaki şüphecilikten derin öğrenmeyi tüm kalbiyle kucaklamaya son derece hızlı bir şekilde geçmesiyle akademi de çarpıcı bir şekilde değişti.
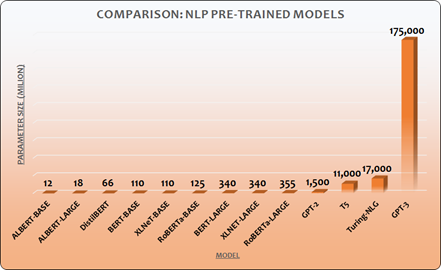
AlexNet’in üzerinden 10 sene geçti. Yapay sinir ağları, gerek günlük yaşantımıza ilişkin problemlere gerek ise endüstriyel alandaki bir çok probleme çözüm oluşturabilir bir seviyeye geldi. Temelde bugün kullanılan yapay sinir ağlarının 10 yıl önce AlxNet’te kullanılan ağlardan bir farkı yok. Ancak çok daha fazla yapay sinir hücrelerine ve çok daha fazla tanımlanabilen bağlantılara sahipler. OpenAI tarafından geliştirilen GPT-3 gibi modeller, super bilgisayarlar ölçeğinde altyapılar ile eğitildi ve insan dilini anlamak, insan gibi içerik üretmek için kullanılmaya başlandı. AlexNet 700 dolarlık bir GPU ile eğitilebilirken, GPT-3’ü eğitmek için binlerce GPU, çok çok daha fazla zaman ve milyonlarca dolar maliyet gerekti.
Bu devasa ölçekli, yüksek maliyetli temel modellerin ortaya çıkması, yeni başlayanlar ve yapay zeka ve makine öğreniminde yenilik yapmak isteyenler için fırsatlar, riskler ve sınırlamalar getiriyor. Gelişmelerin en uç noktasında yer alan Google, Facebook, Microsoft, Amazon veya OpenAI ile rekabet edememelerine rağmen, daha küçük kuruluşlar kendi makine öğrenimi destekli uygulamalarını geliştirmeye başlamak için açık kaynak hazır modelleri de dahil olmak üzere bu devlerin çalışmalarından yararlanabiliyorlar.
AlexNet gibi sinir ağları başlangıçta her görev için sıfırdan eğitildi. Bu yaklaşım, ağların tek bir oyun donanımı, tek bir GPU üzerinde birkaç haftalık eğitim sürecinin yeterli olduğu durumlarda yapılabilir, ancak sinir ağı boyutları, gereken işlemci gücü ve eğitim verisi hacimleri hedefler doğrultusunda ölçeklenmeye başladığında eğitim işi çok zorlaşıyor. Bu, ön eğitim (pre training) olarak bilinen bir yaklaşımın yaygınlaşmasına yol açtı. Bu sayede bir sinir ağı, önce önemli miktarda hesaplama kaynağı kullanılarak büyük bir genel amaçlı veri kümesi üzerinde eğitiliyor ve daha sonra çok daha küçük bir veri seti kullanılarak özel görev için ince ayar yapılabiliyor.
Makine öğreniminin endüstrileşmesi birçok alanı (dil veya konuşma işleme gibi) ele geçirdiğinden ve eğitim için mevcut veri miktarı önemli ölçüde arttığından, önceden eğitilmiş ağların kullanımı son yıllarda patladı. Önceden eğitilmiş ağların kullanılması, örneğin bir start-up’a, sıfırdan başlarken ihtiyaç duyulacak olandan çok daha az veri ve hesaplama kaynakları içeren bir ürün oluşturma olanağı tanır. Bu yaklaşım, araştırmacıların yeni bir görev için önceden eğitilmiş bir ağa hızlı bir şekilde ince ayar yapabildikleri ve ardından sonuçları yayınlayabildikleri akademide de popüler hale geliyor.
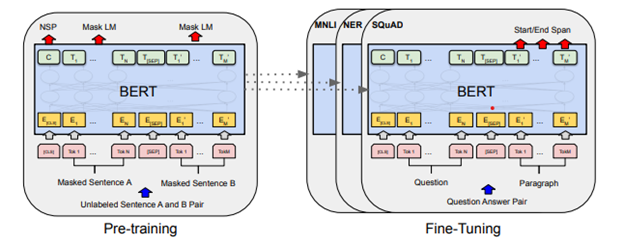
Yazılı metni anlama veya oluşturma, fotoğraf veya videoların içeriğini tanıma ve ses işleme dahil olmak üzere belirli görev alanları için ön eğitilmiş BERT, GPT, DALL-E, CLIP vb modeller, devasa, genel amaçlı veri kümeleri (genellikle milyarlarca eğitim örneği düzeyinde) üzerinde önceden eğitilmiştir ve Google, Microsoft ve OpenAI gibi iyi finanse edilen yapay zeka laboratuvarları tarafından açık kaynak olarak yayınlanmaktadır. Ticarileştirilmiş makine öğrenimi uygulamalarında inovasyon hızı ve bu temel modellerin demokratikleştirici etkisi küçümsenemez. Etrafta yedek bir süper bilgisayarı olmayan sahada çalışanlar için bu açık kaynak ön-eğitilmiş modeller her derde deva oldular.
Paperwork’de de devasa bütçelerle büyük veri setleri ile eğitilmiş açık kaynak bu temel modeller üzerinde, değişik kullanım amaçlarına uygun ince ayar şeklinde eğitimler gerçekleştiriyoruz. Bu eğitimler bile bir kaç GPU ile günler, haftalar mertebesinde çalışma zamanları, onlarca tekrar eğitimler gerektiriyor. Amaca özel ince ayar eğitimler ile modellerin ortaya konulması da işleri sona erdirmiyor. Çünkü gün geçmiyor ki yeni veri setleri ile eğitilmiş yeni devasa bütçeli modeller ve yaklaşımlar yayınlanmasın ve her şeye yeniden başlanmasın. Yapay zeka modellerimizi eğitiyor ve ürünlerimiz içinde kullanıma sunuyoruz. Ve her model çalışması sonunda hemen yeni modellerin eğitimi için yeniden başlıyoruz. Yapay zekayı kullanarak ürünler sunmanın en önemli şartı da burada yatıyor: yaşayan modeller yaratabilmek ve bunun arkasında güçlü bir şekilde durabilmek.















